

You Say You Want a Revolution
You Say You Want a Revolution
AI and the Rush of History

Revolutions rarely go according to plan. Events tend to outrun intentions, outcomes often defy goals, and collateral damage is inevitable. The generative AI Revolution touched off by the introduction of ChatGPT is no exception to the rule.
The unprecedented scale of unlicensed scraping of web content to train AI models has sparked a counter-revolution among web publishers seeking to preserve the value of their intellectual property by erecting barriers against the crawling intruders. In the process, they are wreaking profound changes to the open web.
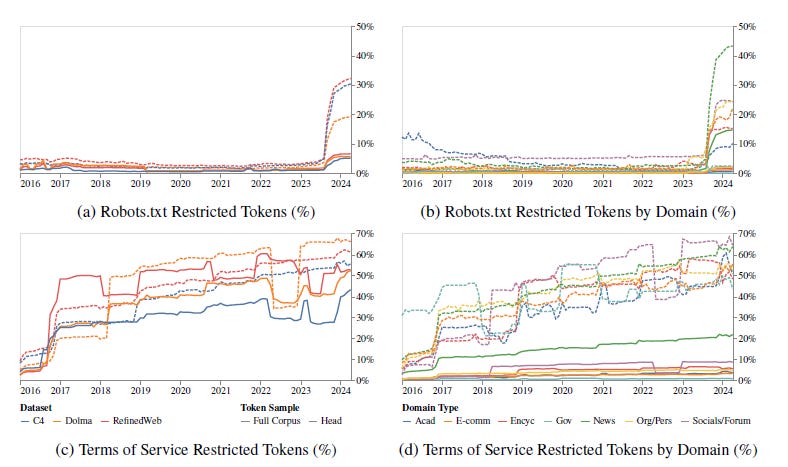
According to a new study by the MIT-led Data Provenance Initiative, the past 12 months have seen the “rapid proliferation of restrictions on web crawlers associated with AI development in both websites’ robots.txt and Terms of Service.”
The researchers audited 14,000 domains over several years that appear in three datasets widely used to train Large Language Models: C4, Refined Web and Dolma. The study recorded the robots.txt instructions for a range of web crawlers but focused primarily on five AI developers, Google, OpenAI, Anthropic, Cohere, and Meta, as well as non-profit web archival organizations such as Common Crawl and the Internet Archive.
For each dataset they selected the top 2,000 domains ranked by the number of tokens in the set, which they designated as the Head sample, comprising the largest, most actively maintained, and critical domains for AI training. News media websites were the most frequently represented domains in all three datasets, followed in varying orders by social media, organizations, government, academic, encyclopedias and e-commerce sites.
The study found that between mid-2023 and mid-2024 the share of robots.txt-restricted tokens among the Head samples rose from less than 3% to 20%-33%. Across the entire corpora, the share jumped from less than 1% to 5%. In relative terms, those figures represent a more than 1,000% increase in restricted tokens among the Head samples in a single year, and a more than 500% increase among the full corpora.
Among news websites in the Head samples, the share or restricted tokens was 45%.
Perhaps unsurprisingly, the OpenAI crawler was the most commonly blocked bot, disallowed by almost 26% of domains across the full corpora. Among domains that block any crawlers, however, 91.5% prohibit the OpenAI crawler. Common Crawl and Anthropic’s crawler tied for second, at 83.4%. The least frequently blocked among the bot’s study is Google’s search crawler, at 17.1% of domains that block any bots.
According to the researchers, the analysis shows a “clear and systematic decline in consent to crawl and train on data, from across the web. To the degree this consent is respected, it also foretells a decline in open data, which may impact more than commercial AI developers, or even AI organizations in general.”
Of particular note to the RightsTech community, however, the study found that in many cases, publishers’ intent restrict access to their content far outstripped what is reflected in their domain’s robots.txt instructions. According to the study, the share of token purportedly restricted by websites’ Terms of Service among the Head samples reached more than 50% among some types of domains by mid-2024. Among news media sites, it reached as high as 70%.
Many of those restrictions, however, are not included in robots.txt files.
Although the robots.txt protocol provides a measure of flexibility in what publishers can restrict and allow access to, the standard itself was originally developed in the 1994 (formally published as a standard in 2022), and was not designed to deal with AI bots.
As a result, the researchers said, “preference signaling mechanisms like robots.txt see errors and omissions in their coverage across AI developers, as well as contradictions with their terms of services—indicating inefficiencies in the tools used to communicate data intentions.”
One other potentially notable finding: the distribution of top domains within training corpora is badly out of step with how most people actually use generative AI tools (the researchers caution the finding is not as definitive as the rest of the study due to methodological limits).
Using data from WildChat conversation logs of users’ real-world interactions with ChatGPT, the researchers found that requests for various types of creative composition, such as fictional stories, role-play and poetry, were included in nearly a third of all queries. Yet creative writings sources are not highly represented among the top domains in publicly available training datasets. That suggests that models trained exclusively on unstructured web data are not well-aligned with how people most frequently want to use generative AI as they often struggle to understand the structure of real-world discourse.
Likewise, sexual role-play represents another frequent use of ChatGPT, appearing in 12% of real-world interactions. Yet sexually explicit content is generally filtered out of training data, reflected in less than 1% of top domains.

That misalignment between how models are trained and how people want to use them not only raises questions about whether developers are accurately targeting the market, but could also hold implications for much of the litigation around the use of copyrighted data for training. The findings suggest that the output LLMs are most frequently asked to generate may not compete directly with the content most commonly used to train them, and is not obviously derivative of the training data.
In a typical four-factor fair-use analysis, the derivative content’s effect on the market for the original is often decisive in determining whether it is infringing. If the effect is shown to be de minimis that could weigh in favor of a finding of fair use.
Taken together, the study’s findings point to an AI Revolution following historic patterns. The headlong rush to develop ever-larger, more powerful AI models is leading to a lot of misdirected effort, investment and angst, and resulting in a lot of unintended consequences.
Most obvious among those consequences is the rapid closing off of the open web as publishers scramble to prevent the wholesale scraping of their content by blocking access to their domains by uninvited bots. That points to a near future in which high-quality training data will be significantly harder for developers to come by without the consent of publishers.
Yet it’s clear from the study that the technical infrastructure to implement a workable regime of detailed and differentiated levels of consent by publishers is badly underdeveloped relative to the demand and need for such tools. As a result, publishers increasingly are adopting an all-or-nothing approach, putting whole swathes of their content off-limits to bots in general, blocking academic, research and other non-commercial users along with commercial ones.
Finally, the findings suggest that the models currently being built with all that money and effort may not even be suited to meet actual market demand.
Maybe it’s time to rethink the whole project.