
We’ve said it before, and now we can say it again: Don’t sleep on the Federal Trade Commission when it comes to a regulatory response to the rise of generative AI. On Friday, Reddit filed an amended S-1 registration statement for its planned IPO in which it disclosed that the FTC has begun investigating its data licensing program for AI training.
“[O]n March 14, 2024, we received a letter from the FTC advising us that the FTC’s staff is conducting a non-public inquiry focused on our sale, licensing, or sharing of user-generated content with third parties to train AI models,” the amended S-1 said. “Given the novel nature of these technologies and commercial arrangements, we are not surprised that the FTC has expressed interest in this area. We do not believe that we have engaged in any unfair or deceptive trade practice.”
It is unclear from the disclosure precisely what the FTC is investigating about the arrangements, although Reddit’s volunteering that it does not believe it has engaged in unfair trade practices might be a tell. Nor is it clear whether the commission’s interest lies primarily with Reddit, or with the third parties involved, one of which is known to be Google.
As the inquiry is non-public, the FTC is not saying anything. But in comments filed with the U.S. Copyright Office for the Office’s policy study of AI and copyright, and in its own inquiry into AI’s potential impact on the creative industries, the FTC has made its concerns about possible abuses in the emerging market for AI training data clear. As it told the Copyright Office:
Conduct that may violate the copyright laws––such as training an AI tool on protected expression without the creator’s consent or selling output generated from such an AI tool, including by mimicking the creator’s writing style, vocal or instrumental performance, or likeness—may also constitute an unfair method of competition or an unfair or deceptive practice… In addition, conduct that may be consistent with the copyright laws nevertheless may violate Section 5.17 [of the FTC Act]. Many large technology firms possess vast financial resources that enable them to indemnify the users of their generative AI tools or obtain exclusive licenses to copyrighted (or otherwise proprietary) training data, potentially further entrenching the market power of these dominant firms.
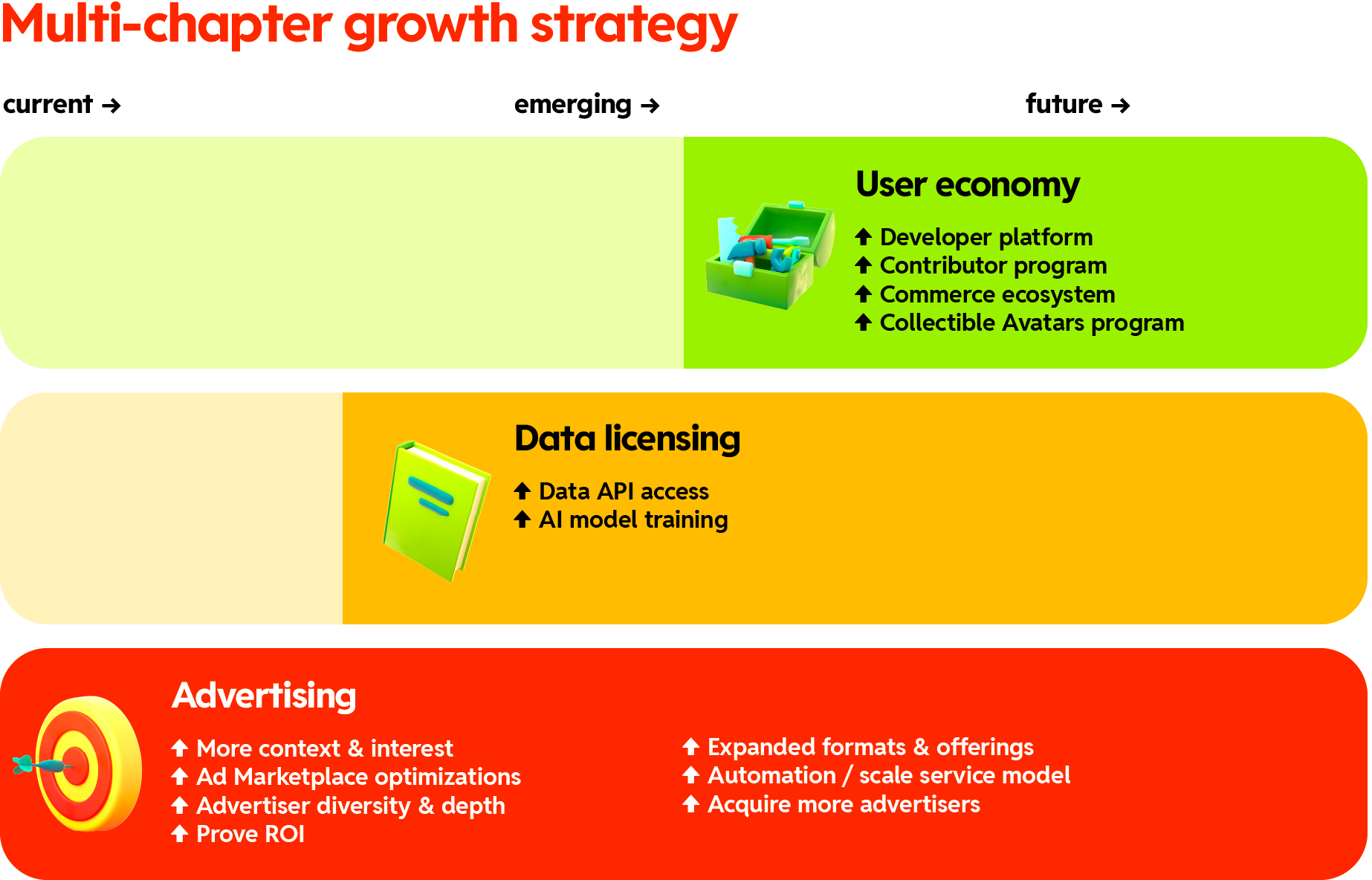
The FTC probe into Reddit’s data licensing program comes at a particularly inopportune time for the company. As it prepared for its IPO, the potential AI windfall from its vast and varied data archive plays a prominent role in its pitch to investors.
According to the S-1, Reddit has entered into data licensing arrangements with various parties “with an aggregate contract value of $203.0 million,” most of which, presumably, involve the use of the data to train generative AI models.
“Reddit data is a foundational piece to the construction of current AI technology and many LLMs,” the filing states. “We believe that Reddit’s massive corpus of conversational data and knowledge will continue to play a role in training and improving LLMs. As our content refreshes and grows daily, we expect models will want to reflect these new ideas and update their training using Reddit data.”
Any potential disruption to that business poses a threat to Reddit’s ex-IPO valuation. As it warns in its amended S-1:
Regulatory engagements can be lengthy and unpredictable. Any regulatory engagement may cause us to incur substantial costs, and it is possible for any regulatory engagement to result in reputational harm or fines, cause us to discontinue or modify our products, services, features, or functionalities, require us to change our policies or practices, divert management and other resources from our business, or otherwise adversely impact our business, results of operations, financial condition, and prospects.
If any of these risks occurs, our business, results of operations, financial condition, and prospects could be adversely affected.
The FTC’s investigation could also have a chilling effect beyond its impact on Reddit’s IPO. Many large rights owners view AI, albeit warily, as offering a potentially lucrative new licensing opportunity for the vast libraries and archives of works they’re sitting on.
Many of the copyright disputes that have arisen between rights owners and AI companies, in fact, would seem to have as much to do with the absence of a working licensing market for training data as with copyright infringement.
The New York Times Co.'s lawsuit against OpenAI and Microsoft over the unlicensed use of Times articles to train ChatGPT, for instance, which the Times filed only after months of negotiations with OpenAI broke down, smells very much like a pricing dispute dressed up as a copyright claim.
It would hardly be the first example of the phenomenon.
As discussed here in previous posts, many of the conflicts that have arisen over the years between rights owners and technology developers that played out as copyright disputes have as much to do with the mechanics of value capture in the new markets created by those technologies as with any of the exclusive rights of copyright owners.
As often as not, those conflicts are fully settled only when a viable licensing market for creative works in those new markets evolves. The decades long copyright dispute between rights owners and YouTube, for instance, only ended with the development of ContentID, which provided a viable mechanism for monetizing copyrighted works on the UGC platform.
The big challenge with generative AI, apart from the head-snapping speed at which the technology is developing, is that very little precedent exists, or even a theoretical model, for determining an equitable price for the use of copyrighted works to train AI systems. The marginal value of any particular data set to the overall performance of an AI model is very hard to quantify.
Reddit was willing to accept relatively modest sums (by tech company standards) for its data because it is keen to demonstrate to investors that it has a viable monetization strategy beyond advertising, which has failed to yield a net profit for the company in 18 years of operation. But rights owners with existing licensing businesses and not on the cusp of an IPO need to think about realizing maximum value from their data, which they clearly view as much higher than the current Reddit benchmark.
For that to happen, however, rights owners need the biggest potential buyers in the market. If those buyers are scared off by the specter of antitrust scrutiny by the FTC or other regulatory agencies, the robust AI licensing market rights owners envision could be stifled before it has a chance to develop.