
Searching Under the Covers
What are your intentions?

Internet infrastructure giant Cloudflare last week published a blog post that accused the AI “answer engine” Perplexity of using stealth tactics to circumvent technical measures used by publishers to prevent unauthorized scraping of their websites by automated web crawlers.
“Although Perplexity initially crawls from their declared user agent, when they are presented with a network block, they appear to obscure their crawling identity in an attempt to circumvent the website’s preferences,” Cloudflare engineers wrote in the post. “We see continued evidence that Perplexity is repeatedly modifying their user agent and changing their source [autonomous system numbers] to hide their crawling activity, as well as ignoring — or sometimes failing to even fetch — robots.txt files.
Perplexity fired back in a blog post of its own accusing Cloudflare of misinterpreting or deliberately mischaracterizing what’s going on.
“When Google's search engine crawls to build its index, that's different from when it fetches a webpage because you asked for a preview. Google's ‘user-triggered fetchers’ prioritize your experience over robots.txt restrictions because these requests happen on your behalf,” the Perplexity post read. “The same applies to AI assistants. When Perplexity fetches a webpage, it's because you asked a specific question requiring current information. The content isn't stored for training—it's used immediately to answer your question.”
Perplexity was a pioneer in commercializing retrieval augmented generation (RAG) technology. Unlike a traditional search engine, which constantly crawls and indexes web pages to be able to direct the user to sources of information relevant to a query, a RAG engine sends out an “AI assistant” (i.e. bot) to crawl the web to find information relevant to the query. Rather than returning a list of links to the sources of the information, however, the bot feeds what it finds to a static LLM (often sourced from a third party) that generates a detailed summary of the information, sometimes with links to the sources, sometimes not.
Perplexity’s argument is that, while technically distinct, the two modalities are substantively the same. In both cases, information is provided in response to a user-initiated action. If a website makes itself available to be accessed via traditional search engine on behalf of a user, it should be no different for user-initiated access via real-time bot.
As one commenter put it on the Hacker News bulletin board, “If I as a human request a website, then I should be shown the content,” adding, “why would the LLM accessing the website on my behalf be in a different legal category as my Firefox web browser?”
As discussed here in a previous post, Cloudflare, one of the largest CDN’s on the internet, offers websites network-level bot blocking via its managed-robots.txt platform, in part precisely to allow sites to charge for access based on the purpose behind a request. It would hardly be the first marketer to conduct “research” that highlights a problem for which it sells a solution.
But the dispute highlights an critical issue, with implications — practical, financial, and legal — for the evolving online information ecosystem.
From the point of view of a website publisher, there is indeed a critical difference between access by a traditional search engine crawler, and access by a RAG bot. In the first case, the publisher is getting something of value in return, in the form of potentially monetizable traffic, even if the search engine operator is earning the lion’s share of the traffic’s value. In the latter, even that lopsided bargain is broken. Traditional and AI-augmented search are not simply different means to accomplish the same ends, they are different means to accomplish very different ends, with very different effects.
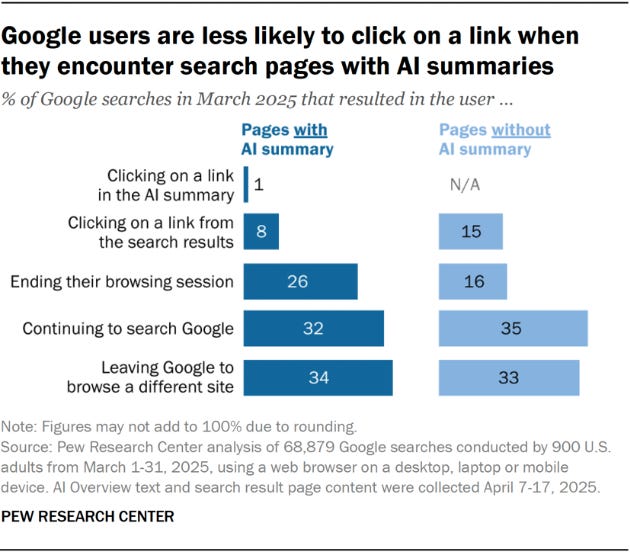
As detailed in a study released last month by the Pew Research Center, the effect produced by AI search is anything but trivial. In its research on Google Overviews, which displays AI-generated summaries above traditional links in response to search requests, Pew found that users were only half as likely to click on a link if they’re provided an AI summary. Only 1% of users clicked on a source link within an AI summary, and more than a quarter ended their browsing session after perusing a summary without pursuing additional research on a topic.
A separate study, by Authoritas, found that AI summaries can lead to as much as 80% fewer click-throughs to publishers’ websites, and that a site that previously ranked first in a search result could lose 79% of its traffic from a query if the results were displayed below an AI summary.
For better or worse, the implicit crawls-for-clicks bargain has been foundational to the internet economy since Google perfected the search engine. Generative AI has already broken that bargain by scraping sites of their content to feed their models while returning little if any value to the publishers. AI-augmented search has only widened the breach by deprecating the clicks publishers were still getting.
It’s hardly a wonder, then, that publishers are alarmed at the rise of AI-augmented search engines, and are adopting more aggressive measures to try to keep their crawlers out.
In fairness to Perplexity, it’s hardly alone in evading anti-scraping strategies. In their unquenchable thirst for data, some AI companies are resorting to all sorts of underhanded tactics to ferret it out. They’re using proxy services and IP rotation to disguise the identities and motives of their crawlers. They’re scraping browser caches and deploying CAPTCHA-hacking tools, and Just this week, Reddit announced it will limit the data it makes available to the Internet Archive because AI companies are scraping the Wayback Machine for Reddit’s paywalled content.
With the internet’s long-standing social contract breaking down, perhaps irreparably, the fundamental question left is whether the intent of a user seeking access to a site — whether human or robot — should be a factor in the interaction.
Copyright law, in general, allows a rights owner to license certain uses of their work by other parties but withhold the right to make other uses: You can do this with my writing, but not that. But their are circumstances where those conditions do not hold. Certain uses are permissible with or without the rights owner’s approval, and where so the user’s intent in obtaining the work is not a controlling factor.
In the recent Kadrey v. Meta case, for instance, the court emphasized that fair use primarily is concerned with the purpose of the use, not the means by which it was effected.
“The plaintiffs are wrong that the fact that Meta downloaded the books from shadow libraries and did not start with an “authorized copy” of each book gives them an automatic win, Judge Vince Chhabria wrote. “To say that Meta’s downloading was ‘piracy’ and thus cannot be fair use begs the question because the whole point of fair use analysis is to determine whether a given act of copying was unlawful.”
On the other hand, Cloudflare’s network-level bot blocking system could reasonably be described as a technical measure that controls access to copyrighted works. It blocks bots and crawlers by default, and requires them to, if effect, declare their purpose for requesting access in their headers. Publishers can then set terms and conditions for granting access based on the bot’s declared purpose.
In the world of physical media, circumventing such technical protection measures would likely violate §1201 of the Digital Millennium Copyright Act. And courts that have ruled in DMCA cases have generally held that the purpose in circumventing a TPM, even if to make otherwise lawful fair use of the underlying content, is not relevant to the analysis.
So there is precedent of a sort on both sides of the intent question. Sometimes the intent of the user is none of the rights holder’s business, sometimes a rights owner’s interests override a user’s intent.
But in the topsy-turvy realm of AI, the usual roles of users and rights owners are reversed. User rights favor the user, while access rights favor the rights holder.
Just another way AI has turned old assumptions on their head.