Searching the News With ChatGPT
Often wrong, but rarely in doubt

News publishers have been among the most active rights holders in challenging technology developer over the unlicensed use of their copyrighted works to train generative AI models, from the New York Times’ 2023 lawsuit against OpenAI and Microsoft, to last week’s action by a group of leading Canadian publishers, also against OpenAI.
News media companies have also been among the most active at striking licensing deals with AI companies for the use of their articles in training, highlighting the uncertainty and division among publishers as to how best to address the head-snapping rise of AI.
The emergence of AI-powered search engines, such as Perplexity, Google’s Overviews and the recently introduced ChatGPT Search from OpenAI, has raised the stakes for publishers still higher. The new tools leverage Large Language Models (LLMs) to generate summaries of information retrieved from the web, often sourced from news websites but at times presented without attribution or links to the original sources.
Once again, publishers are divided on how best to respond. Many have moved to block AI search crawlers from accessing the domains, while others, such as Der Spiegel, TIME, Condé Nast and Financial Times, have agreed to cooperate in the hope of ensuring their content is properly and prominently credited.
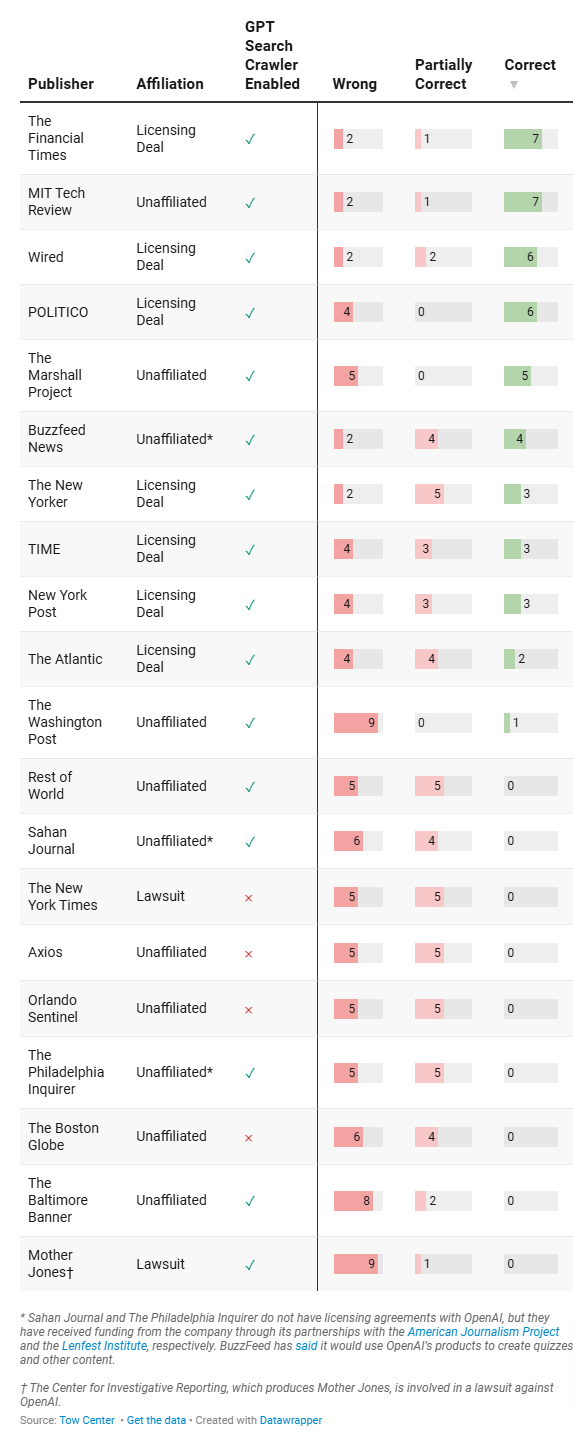
According to a troubling new study by the Tow Center for Digital Journalism at Columbia University, however, it may not matter which way publishers come down on the question, at least in the case of ChatGPT Search. Whether they block or permit their sites to be crawled is appears only minimally correlated with whether their work is cited correctly.
The study looked at 20 randomly selected publishers representing a mix of those that have sued OpenAI, those that have struck deals with the company, and those that have done neither (“unaffiliated” in the report’s findings). Some have blocked AI crawlers, and some that have permitted scraping. For each publisher, the researchers selected 10 block quotes (200 block quotes in all), and asked the ChatGPT search engine to identify the source and the date of publication for each.
In all cases, the correct identification of the block quotes appeared within the top 3 search results when plugged into Google or Bing. Not so with ChatGPT. Of the 200 quotes, ChatGPT correctly identified both the source and date of publication in only 47 cases (23.5%). The rest were either entirely wrong, or only partially correct, such as getting the date of publication correct but misattributing the quote.
Worse, of the 153 cases where it got the identity of the quote wrong, or only partially correct, the chat bot provided the incorrect information with complete confidence in 146 of them. In only seven incorrect cases did the response suggest any uncertainty, such as by saying “might,” or “it’s possible,” or acknowledging “I couldn’t locate the exact article.”
Most troubling for publishers, however, is that it made little difference whether they had blocked access to their sites by OpenAI’s search crawler. In most cases where it could not have accessed the correct source of the quote, ChatGPT simply made up (hallucinated) a citation.

Now, for the obvious caveats: It’s a small study, involving a single search bot. Your mileage may vary. But it does lead you to wonder whether OpenAI, or any AI developer for that matter, really understands the products it’s unleashing on the world.
In announcing ChatGPT search on Halloween, OpenAI made much of having “collaborated extensively with the news industry,” and of “carefully listen[ing] to feedback” from participating publishers, including Associated Press, Axel Springer, Condé Nast, Financial Times, Hearst, Le Monde, News Corp, Reuters, The Atlantic, Time, and Vox Media, among others.
If true, that “extensive collaboration” would appear to have failed to uncover some fundamental flaw in the system’s design. If OpenAI was just blowing smoke about “carefully listening” to publisher feedback to get some PR cover… well, that might be even worse.
Either way, the study’s findings suggest that, for news publishers, finding value in AI-powered search is a more complicated question than simply whether to license their content, or not.